Article Published: 19th September 2025
Your network can’t afford an hour of downtime
For the full details, read this blog article and then download our whitepaper.
Download the Whitepaper Now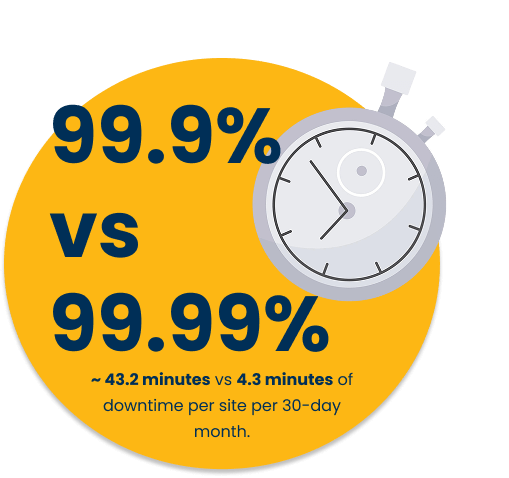
Imagine this: a busy rapid hub, bays full, then a fibre cut and a summer storm arrive on the same afternoon. Sessions stall, payments time out, drivers get frustrated, reviews go south. In public charging, every preventable minute offline chips away at trust.
Most charging projects are engineered to install chargers. The best-performing networks are engineered to stay online when the grid wobbles, the internet blinks or a platform hiccups. The difference isn’t magic—it’s a handful of decisions you can put in place now.
Here’s the good news: you don’t need a total rebuild. Start with a few system-first choices that harden your sites and protect your brand.
By the end of this blog, you’ll know:
- The five reliability decisions that move uptime the most
- A five-minute “what if?” drill to pressure-test any site
- How our white paper and toolkit help you turn ideas into an action plan
Grid insight and charger engineering: build for the real world
“Hardware reliability is the foundation—not the weak link.”
Anyone can publish a spec. Fewer can keep a public site running when power quality dips, comms fail over, and transactions must still flow. That’s where grid-grade design meets charger know-how.
Key design considerations built into resilient public sites:
- Voltage fluctuations — Controls ride through short dips instead of rebooting.
- Power quality stress — Proven tolerance for surges, dips and nuisance trips.
- Communications failover — Dual WAN with automatic switchover.
- Graceful offline operation — Offline authorisation lists and OCPP buffering so sessions keep starting.
- Diagnostic monitoring — The right telemetry to spot issues early and recover fast.
Tip: Ask vendors for measured failover times and validated ride-through, not just “supported.”
Five decisions that change availability
- Keep the brains alive
Short disturbances shouldn’t knock out controls. Add ride-through or UPS hold-up for PLCs, comms and metering. - Assume the internet will blink
Use dual paths and test switchover (<30 seconds). Maintain an offline authorisation list and store-and-forward OCPP. - See problems early, fix them fast
Instrument start/stop failures, payment retries, connector temperature and error codes. Give your NOC clear runbooks. - Design for fast swaps
Stock a regional spares kit and use field-replaceable modules. Target MTTR < 2 hours on priority hubs. - Write SLAs to reality
Define response and restore by site tier, include failover tests, and report against them.
Run this five-minute “what if?” drill today
What if a regional fibre cut and a thunderstorm hit this afternoon?
- Will comms fail over in under a minute—and will new sessions still start?
- How long can you buffer transactions locally?
- Do controls ride through brief voltage dips without rebooting?
- Can first-line support safely run a remote restart with a rollback path?
- If a connector is failing, can you hot-swap within your restore target?
If any answer is “not sure,” you’ve just written this week’s action list.
What you’ll find in the whitepaper (and why it helps)
- Resilience patterns you can adapt to hubs, kerbside clusters and retail car parks
- A practical operations playbook for observability, runbooks, firmware and spares
- A light compliance view connecting reliability, payments and support
- A short what-if scenario to benchmark your current setup
Conclusion: make the last nine your advantage
Uptime isn’t a slogan—it’s a system. Keep the brains alive, expect comms to blink, see problems early, design for fast swaps, and promise only what you can prove. Do that consistently, and the “last nine” becomes part of your brand.